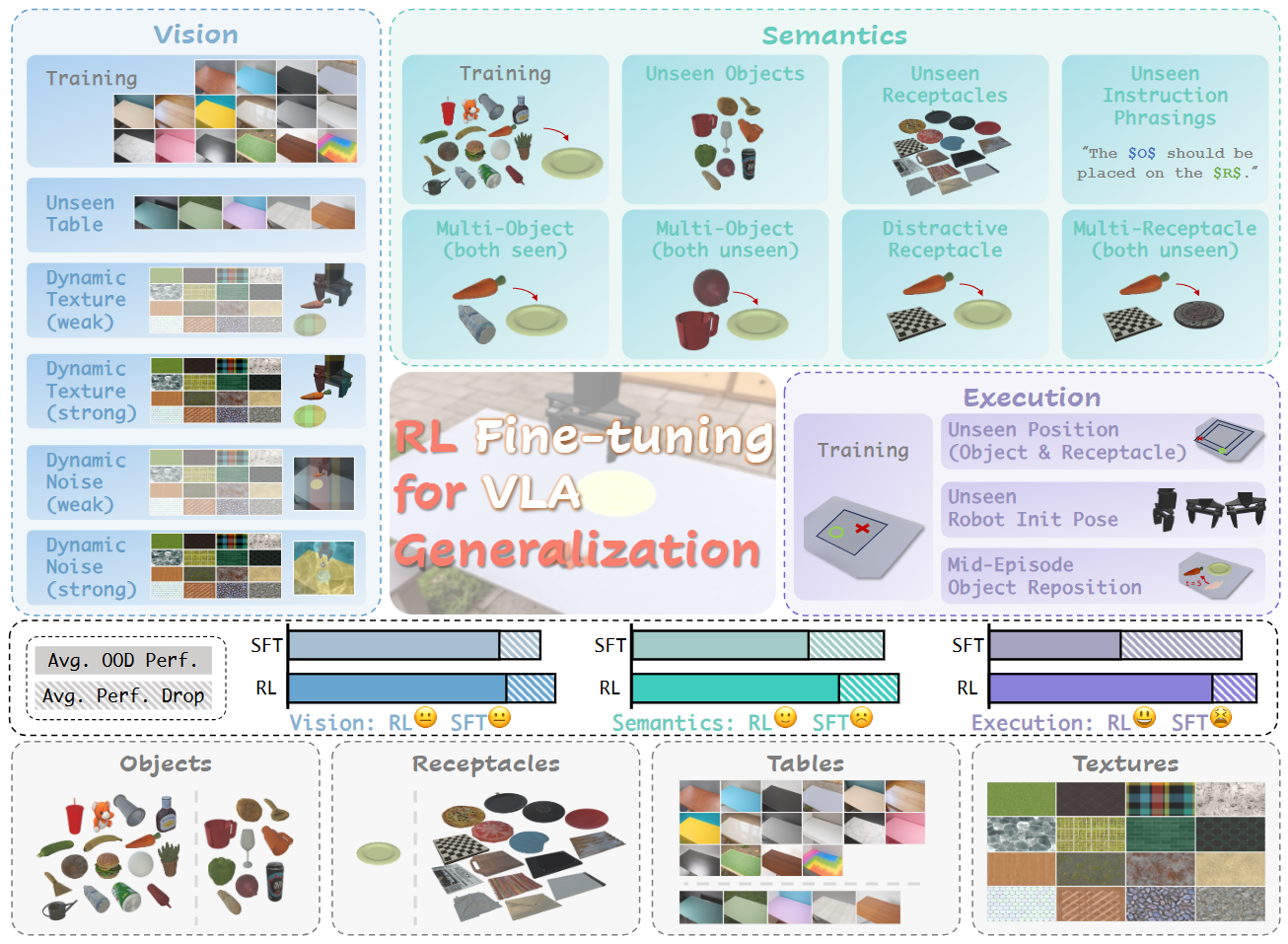
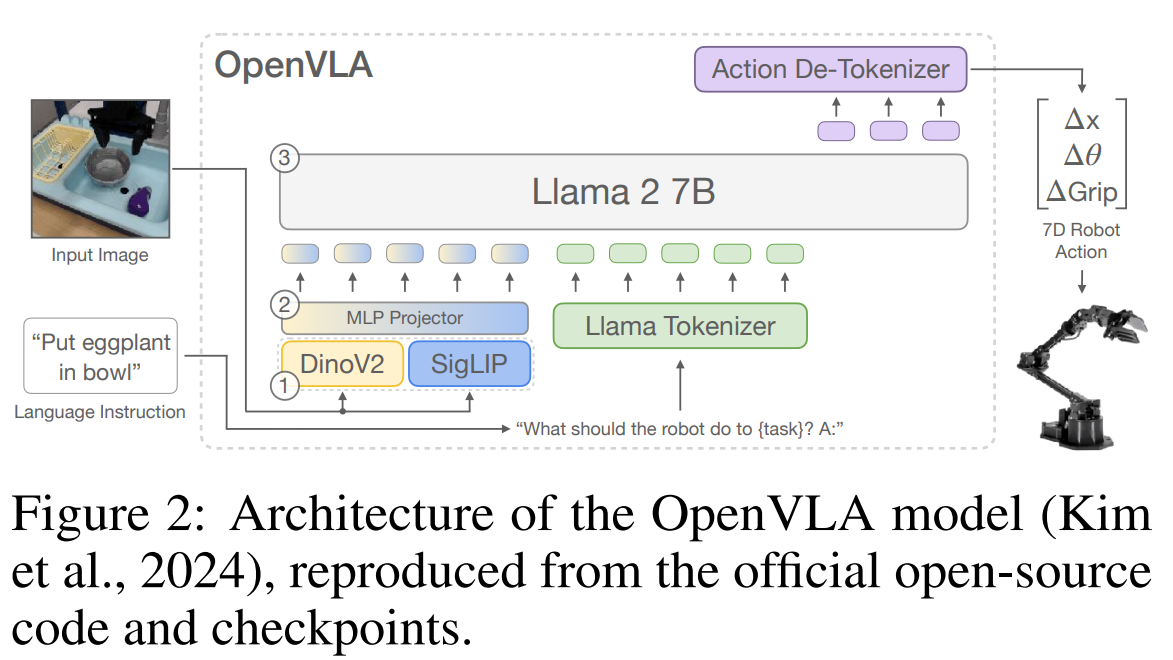
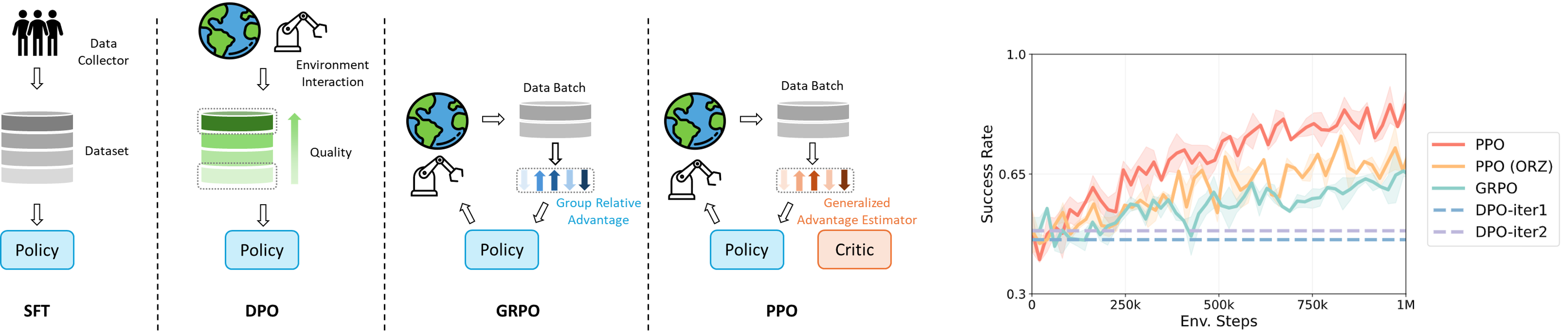
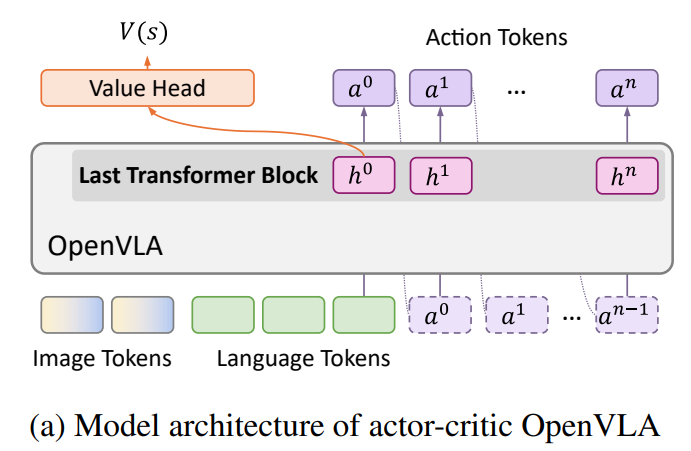
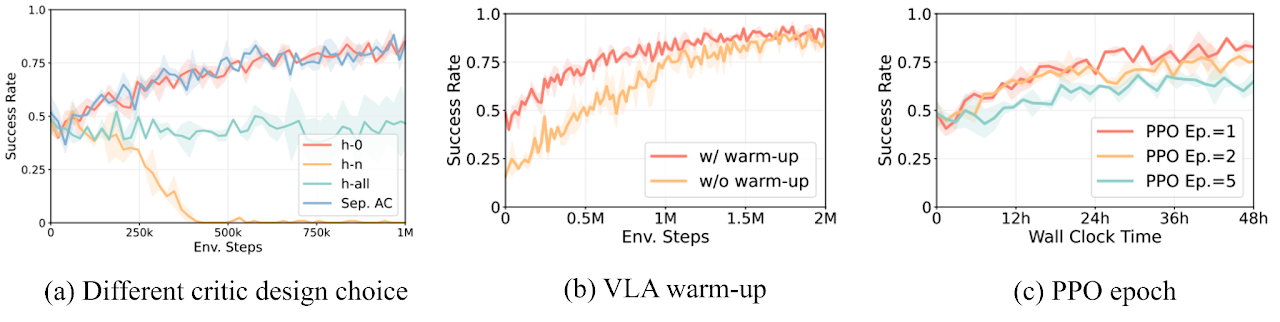
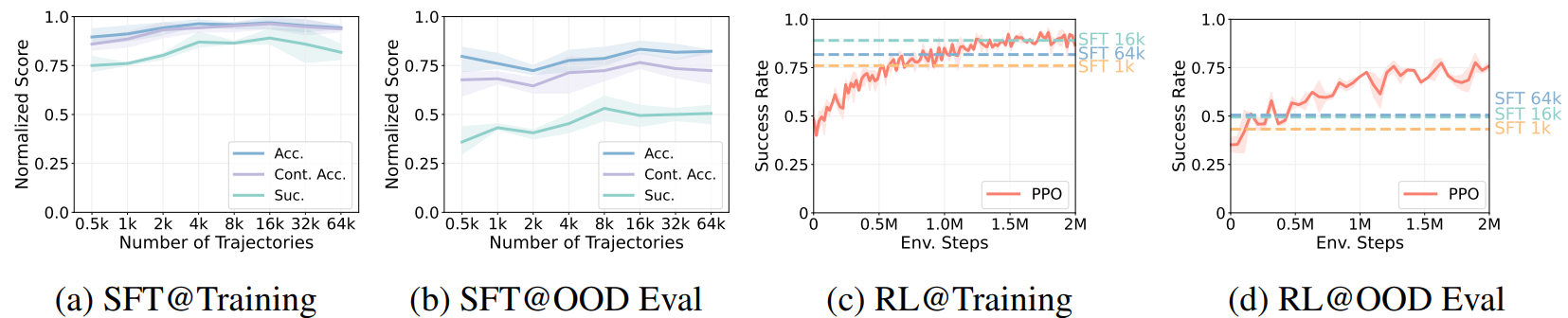
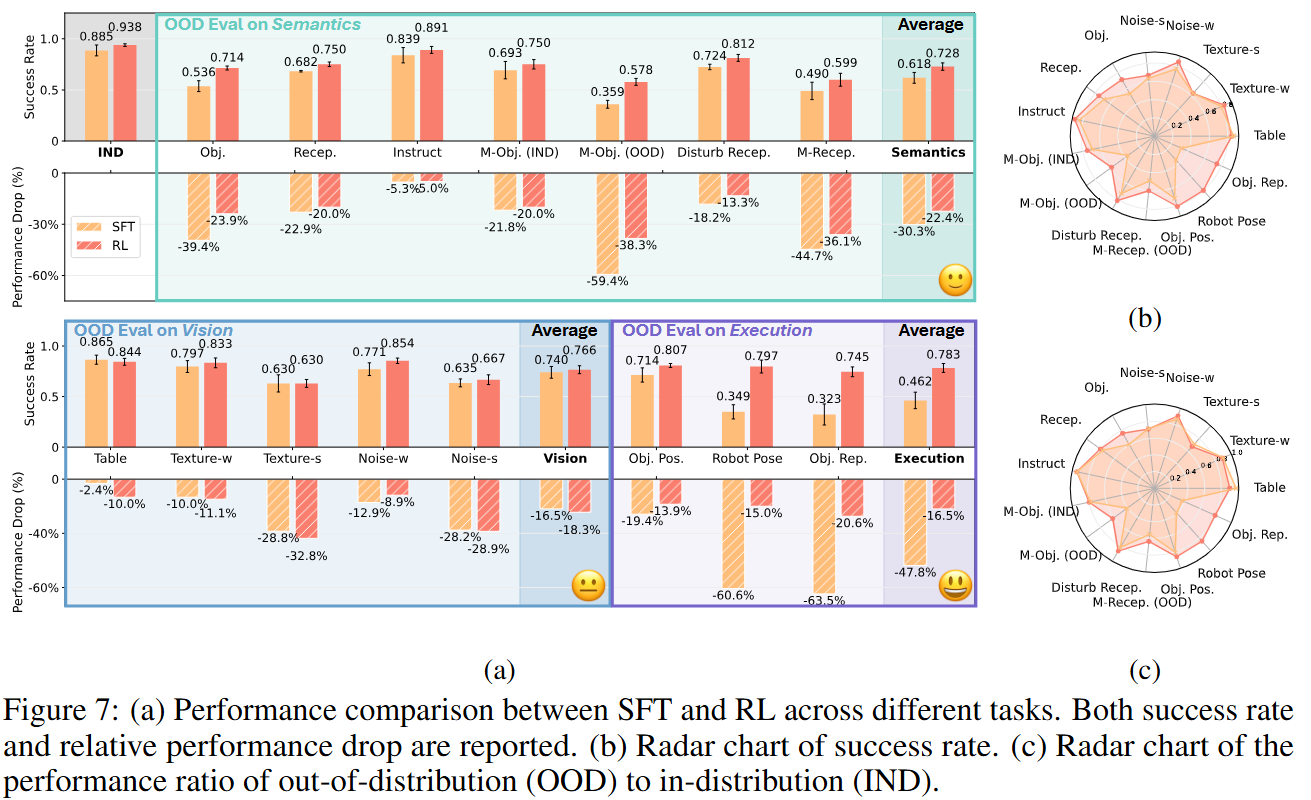
Inspired by prior works (Fan et al., 2025; Stone et al., 2023) and the concept of Vision-Language-Action
models, we define three dimensions of generalization:
Vision: We include both foreground and background changes, as well as image-level dynamic noise.
Semantics: We consider unseen variations in objects, receptacles, and instruction phrasings, as well
as
several new tasks.
Execution: We investigate changes in the initial positions of object and receptacle, as well as robot
initial pose.
In the training setting, we randomise along three axes: 16 tables (Vision), 16 objects (Semantics),
and
perturbations of object and receptacle poses (Execution).
At test time we hold at least one of these factors out of distribution, introducing 9 novel objects,
16
unseen receptacles, 5 new table surroudings, and 16 distractor textures.